
以为遭遇了 DDoS 攻击,实则却是百度爬虫
- 鄢云峰
- 2023-11-02 16:57:39
- 589
- 2
- YYF
博客最近上线了一个访客记录的功能,此功能的业务逻辑很简单:就是当用户访问博客时,获取其 IP 地址,然后判断此 IP 地址在数据库中是否存在,如果存在则忽略不计,如果不存在则记录下来,存入数据库。
通过记录 IP 我们就可以粗略的得到博客的真实访问人数了,之所以说是粗略,是因为一个 IP 并不能百分百就代表着一个人。既然拿到了用户的访问记录数据,那么在博客首页中我们就可以展示访客计数了
然而在前几天,我在查看后台访客记录数据的时候,发现了一批异常的 IP 数据,具体截图如下
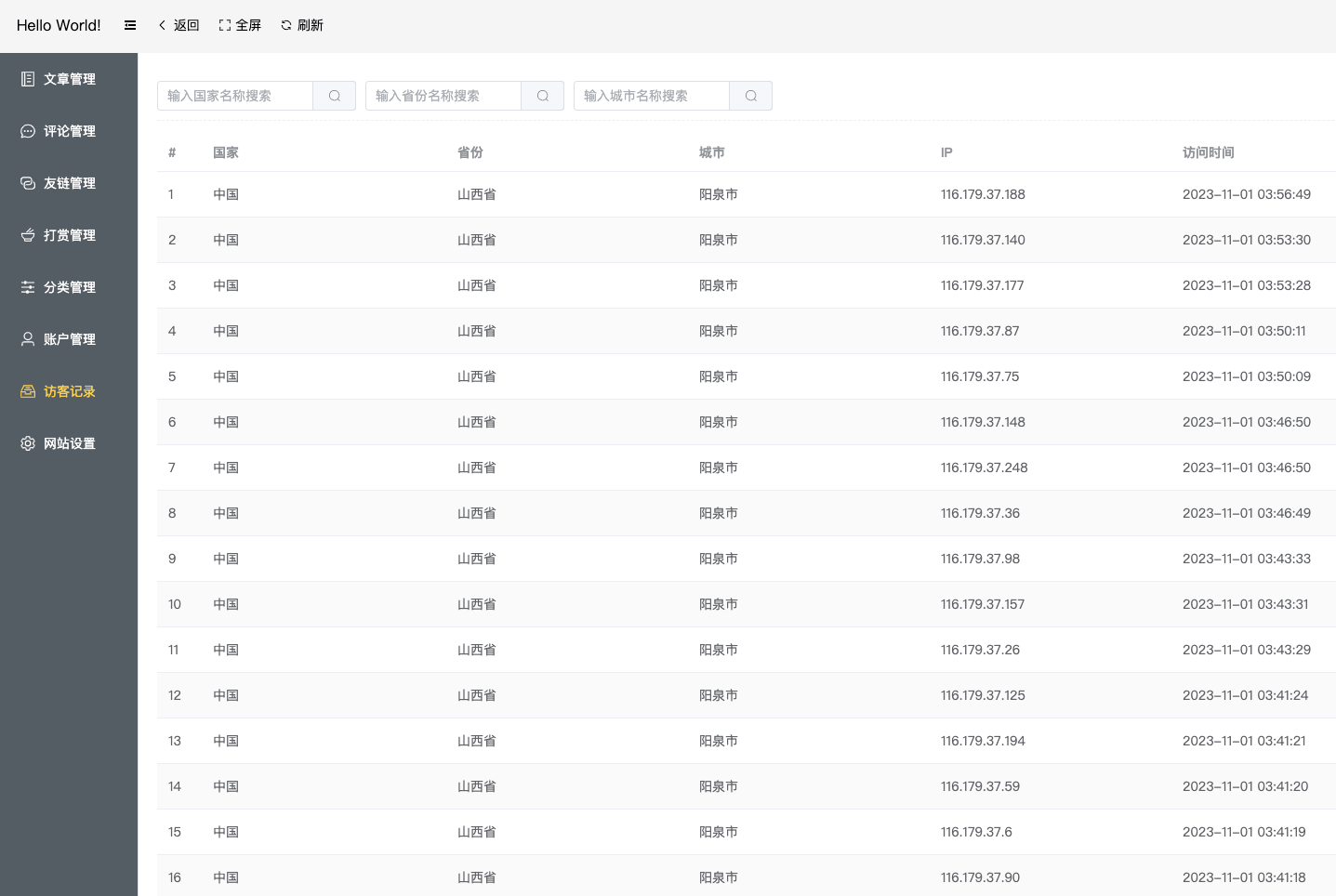
看到这些数据,第一反应是:有人在攻击我?频繁的切换 IP ,这么锲而不舍,也太狗了吧!然后我还跑到技术群里喊了一声,问是不是群友在拿我的网站练手!因为此前群里有卖 DDoS 防护软件的,保不准人家来恶心下我,哈哈哈~
因为我用的 nginx 服务器,而 nginx 本身就提供有访问日志和错误日志,所以我们可以直接去看 nginx 的访问日志,看下能不能找到有用的信息。日志文件的路径 nginx -> logs -> access.log。然后我们打开 access.log 文件,搜索 IP 地址前缀 116.179.37 ,这样我们就可以看到如下图所示的日志信息

通过日志信息我们发现,这些 IP 其实都是百度的蜘蛛爬虫,并非是有人恶意攻击,虚惊一场。问题排查也算是到此结束了,搜索引擎的爬虫爬取是正常的,因为不爬取内容,就无法收录网页。
那么现在还剩下一个遗留问题,那就是如何过滤掉爬虫,不要把爬虫当成访客!其实过滤爬虫也很简单,因为正规爬虫都是带有标识的,比如百度爬虫的标识 Baiduspider,谷歌爬虫的标识 Googlebot,必应爬虫的标识 bingbot 等等。那么我们该如何拿到这些标识呢?
获取标识的方法我们可以通过 UA ,也就是 user-agent,因为 http 请求的请求头普遍都会带有 user-agent 字段,我们通过获取 user-agent ,然后再对其进行字符判断,即可得知当前请求是否是爬虫。
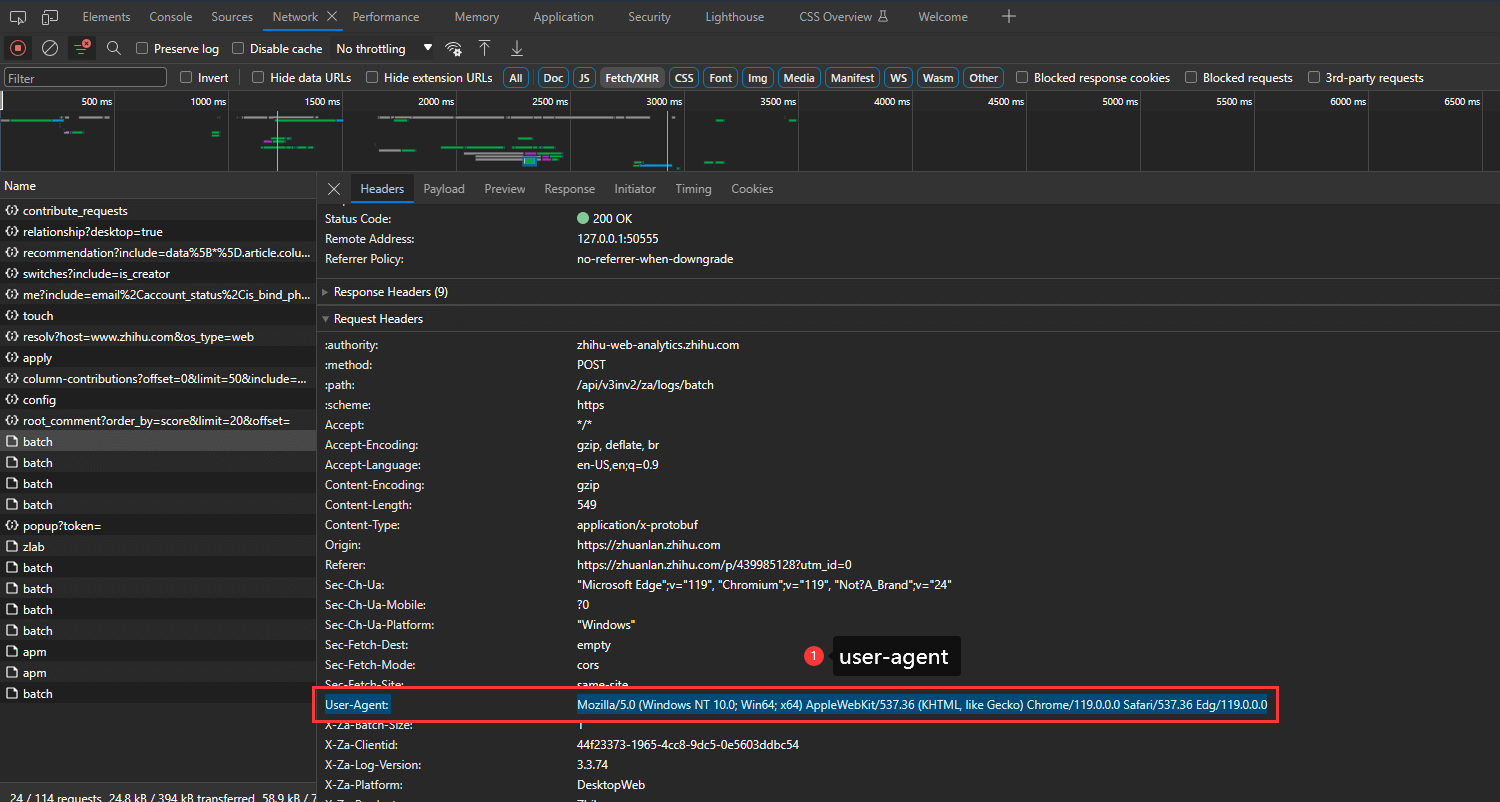
下面是 nestjs 中判断爬虫的一个示例,供大家参考
const ua = req.headers['user-agent']
const isBaiduSpider = /Baiduspider/i.test(ua)
const isGooglebot = /Googlebot/i.test(ua)
const isBingbot = /bingbot/i.test(ua)
const is360Spider = /360Spider/i.test(ua)
if (isBaiduSpider || isGooglebot || isBingbot || is360Spider) {
// 是爬虫
} else {
// 不是爬虫
}通过正则判断 UA 字符串中是否包含有各个爬虫的标识,从而过滤掉爬虫